Warning
You are reading the documentation for an older Pickit release (2.0). Documentation for the latest release (4.1) can be found here.
Explaining the Teach detection parameters
The Pickit Teach vision engine is designed to detect complex 3D shapes. This article explains its detection parameters.
M-HD preset(M-HD camera only)

In this tab the preset for the M-HD camera is chosen. This preset determines the settings of the camera and how a point cloud is captured.
This guide helps you chosing a good preset for your application, How to choose the correct M-HD preset.
Define your model(s)
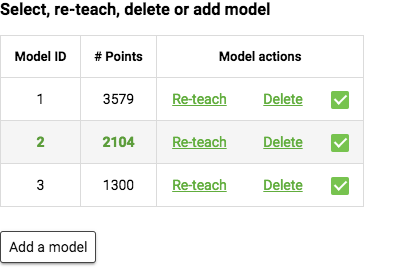
A list of thaught models is shown accompanied by their ID and the number of points. By default, there are no models defined.
Add a model
Press Add a model to add your first model, the points currently visible within the ROI are now saved into a model. When the model is successfully created, the model will automatically be shown in the Model view.
In one product file up to 8 different models can be taught. This means that Pickit Teach is capable of looking for 8 different shapes in one detection. See How to make a robot program with multiple models on how you can use the model id in a robot program.
Re-teach a model
You can always reteach a model by pressing Re-teach for a specific model. By pressing this button, the points currently visible within the ROI are saved into the model.
Warning
When re-teaching a specific model, the point-cloud data from the previous model is overwritten. This action cannot be undone.
Delete a model
To delete a model, press Delete for the specific model. The action needs to be confirmed in deletion popup.
Warning
Model ID’s will be reassigned after deleting a certain model. Always check your robot program after deleting models.
Warning
Model data will be lost after deletion confirmation and cannot be restored.
Select and visualize a model
A model can be selected by clicking on the row. When the model is loaded, the model will automatically be shown in the Model view.
Enable or disable a model
Each model can be included or excluded from the detections, this can be done by check (Enable model - Default) or uncheck (Disable model). When disabling a model, the detection algorithm will completely ignore that specific model.
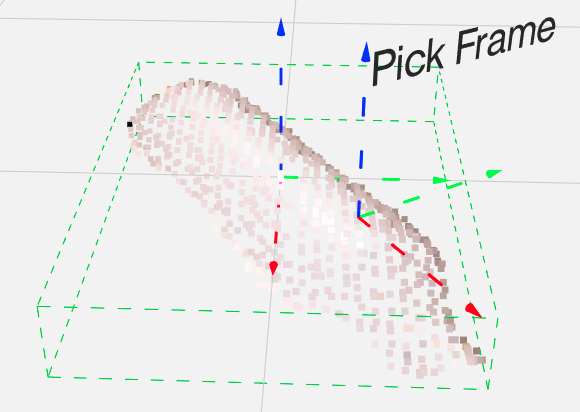
Pick frame
The pick frame is the location where the TCP of the robot will be guided to. The location of the pick frame can be visualized from the Model view. By default, Pickit Teach provides an initial pick frame, but this will in general not be the best choice. It’s possible to specify the desired pick frame as a positional and rotational offset with respect to the object model.
Matching tolerance
If the distance between a detected scene point and a point of your model is below this position tolerance value, then this scene point will confirm the model point. This parameter has a big impact on the scoring of the Minimum matching score.
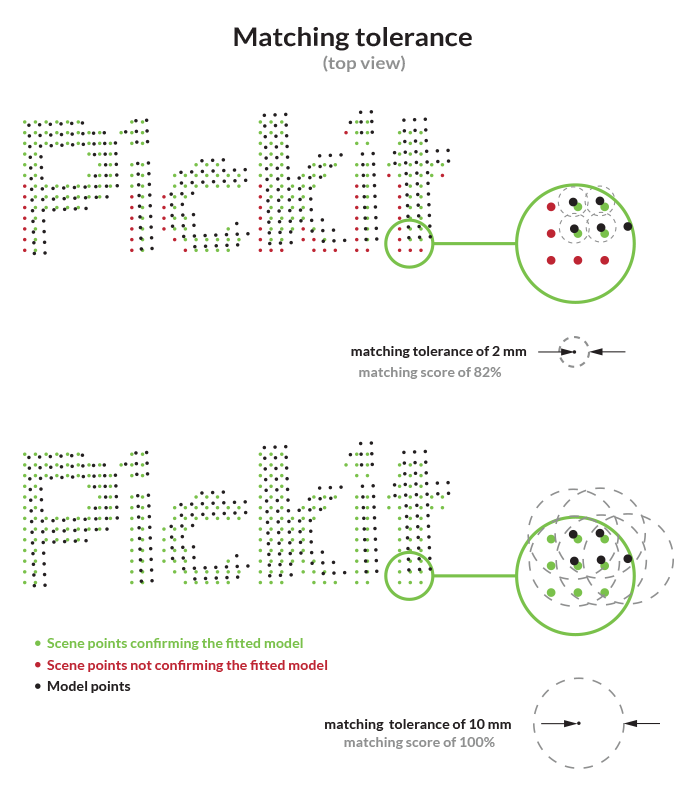
Minimum matching score
Minimum percentage of model points that need to be confirmed by scene points, for the detected object to be considered valid.
Optimize detections
Image fusion(M/L camera only)
Image fusion is the combination of multiple camera captures into a single image. Enabling image fusion can provide more detail in regions that show flickering in the 2D or 3D live streams. Flickering typically occurs when working with reflective materials. There are three possible fusion configurations: None, Light fusion and Heavy fusion.
Image fusion can increase total detection time by up to half a second. The recommended practice is to use None in the absence of flickering, and try first Light fusion over Heavy fusion when flickering is present.
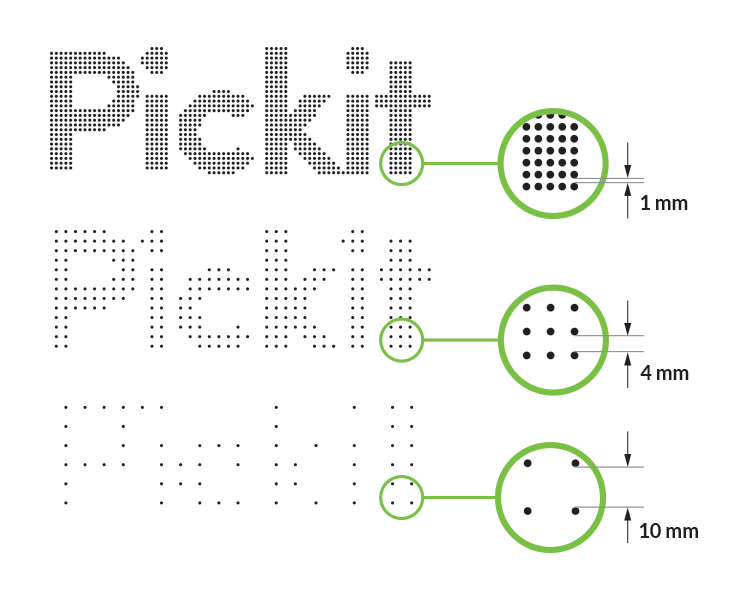
Scene downsampling resolution
The downsampling resolution allows reducing the density of the point cloud. This parameter has a big impact on detection time and accuracy. More points lead to higher detection times and higher accuracy, fewer points to lower detection times and lower accuracy.
In the illustration, you can see an example of setting the scene downsampling parameter to 1 mm, 4 mm and 10 mm.
Detection speed
With this parameter, you can specify how hard Pickit Teach tries to find multiple matches. Slower detection speeds are likely to produce more matches. There are three available options:
Fast Recommended for simple scenes with a single or few objects.
Normal This is the default choice and represents a good compromise between a number of matches and detection speed.
Slow Recommended for scenes with many parts, potentially overlapping and in clutter.
Example: Two-step bin picking.
Pick an individual part from a bin using Normal or Slow detection speed and place it on a flat surface.
Perform an orientation check for re-grasping using Fast detection speed, as the part is isolated. Grasp and place in final location.
Detection precision
Apart from the above choice, you can instruct Pickit Teach to favor being more precise or to potentially find more objects. This choice has a negligible impact on detection times. In most cases, selecting more precise yields a good number of matches per detection run, and is the recommended default.