Warning
You are reading the documentation for an older Pickit release (3.2). Documentation for the latest release (4.1) can be found here.
Explaining the DeepAL detection parameters
This article presents the detection parameters associated to the Pickit DeepAL, a detection engine for depalletization applications.
Define models
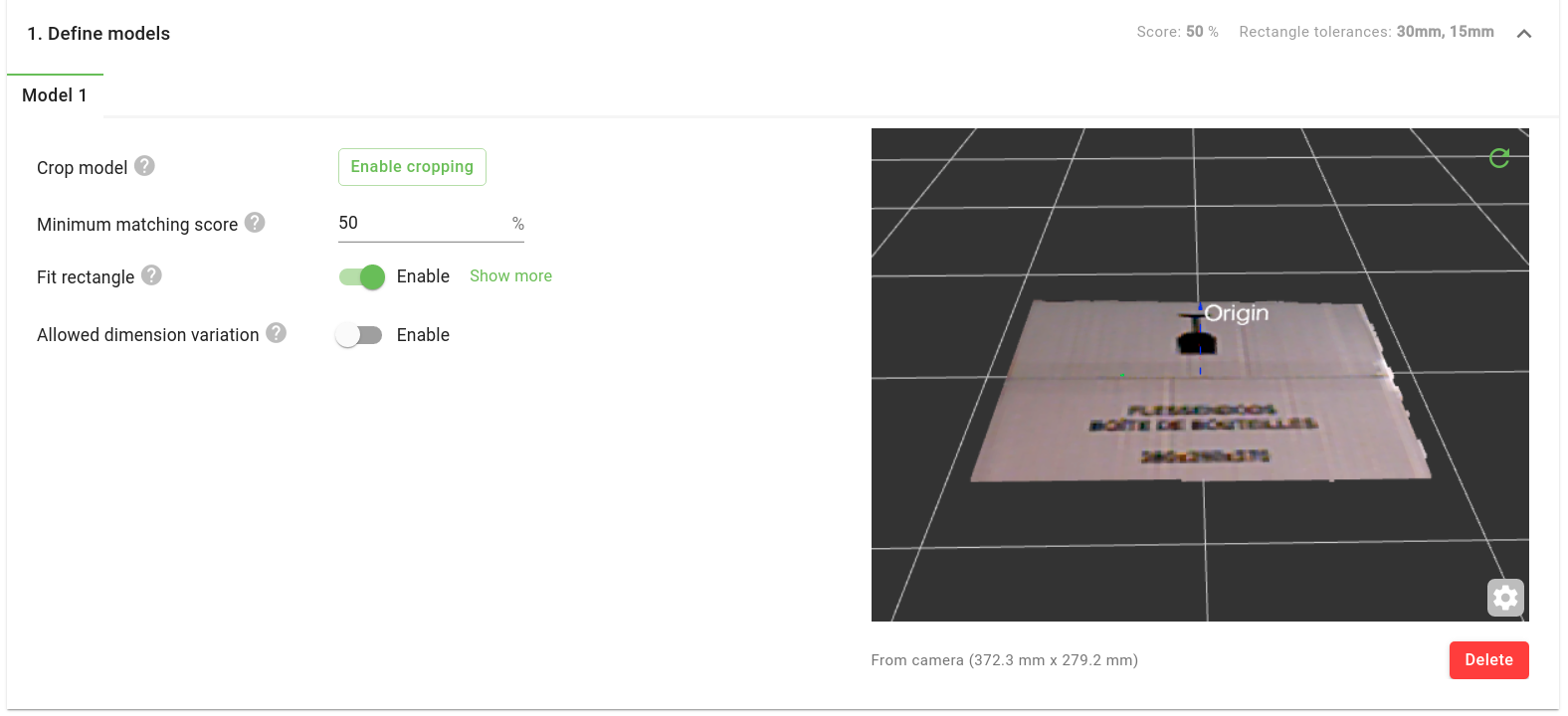
Teach a new model: Press Teach from camera and the points currently within the ROI will be saved to a model. On successful creation, the model will be visualized in the 3D model viewer along with its dimensions. You can crop the model to refine its bounds and make sure that no extraneous points are included.
As opposed to other engines like Teach, you can only have one DeepAL model per product file.
Tip
When using DeepAL, it’s recommended to enable the dynamic box-based ROI filter, which keeps the top-most contents of the ROI. When detecting flat parts like boxes, this filter will only keep the boxes in the top-most layer, even if multiple layers are contained in the ROI box. This is useful both during model teaching and part picking:
Model teaching: If you have a full pallet layer and want to teach a new model, you can simply take one box and place it on top of the layer and press
Teach from camera. You will have a single-box model, no cropping required.Part picking: You guarantee that the top-most layer is emptied first.
Delete a model: To delete the current model, press the Delete button.
Minimum matching score: Percentage of how much of the model is expected to be found in the scene for a detection to be valid.
Fit rectangle: DeepAL is frequently used to detect rectangular boxes, but is not limited to them. It can also be used on other shapes like circular buckets or non-rectangular boxes.
When detecting rectangular boxes, enabling this option performs an additional rectangle fitting step, which can improve detection accuracy.
Allowed dimension variation: Rejects detections whose dimensions differ from those of the taught model by more than a specified value.
Optimize detections
Image fusion (SD cameras only)
Image fusion is the combination of multiple camera captures into a single image. Enabling image fusion can provide more detail in regions that show flickering in the 2D or 3D live streams. Flickering typically occurs when working with reflective materials. There are three possible fusion configurations: None, Light fusion and Heavy fusion.
Image fusion can increase total detection time by up to a second. The recommended practice is to use None in the absence of flickering, and try first Light fusion over Heavy fusion when flickering is present.
Detection speed
This parameter influences how the model size is reduced by means of downscaling.
Slow Produces the highest-quality matches, and no downsampling is performed. It’s recommended to start with this setting.
Normal and Fast add increasingly more downsampling to reduce the model size, lowering the quality of the matches, but increasing the detection speed.